

Instructions and tips for using the BlackLab tool and its different search levels
The interface and the different search modes
Simple Search (Simple)
Simple search allows you to perform a quick search by words or lemma.
To perform a search, simply enter the word you are looking for in the search bar and press Enter or click on Search.
Please note: in Simple search, searches are case-insensitive, i.e. accents or upper and lower case letters are not taken into account: thus the searches "mère", "mere", "Mère", "Mere" will provide the same results.
Additionally, it is possible to use wildcards to refine the search level:
- * : The asterisk represents any character appearing zero or more times.
Example: a search for "me*" will find all words beginning with 'me-';
a search for "*me" will find all words ending with '-me';
a search for "m*e" will find all words beginning with 'm-' and ending with '-e';
a search for "m*e*" will find all words beginning with 'm-' and containing an 'e';

-
? : The question mark represents an unknown character.
So, entering 'm?' will search for all words in letters starting with an 'm-' followed by a single character;
a search for 'm??' will search for all words starting with an 'm-' followed by two characters;
a search for '????m' will search for all words ending with a '-m' preceded by four characters;
- | : The vertical bar symbolizes 'or' and offers an alternative.
If you enter a search like 'm*|n*', you express that you are looking for all strings of characters starting with 'm' or all strings of characters starting with 'n'.
Extended Search (Extended)
Extended search is an extension of Simple search and allows you to find all occurrences of a token with its specific attributes.
A token generally represents a single word and is the smallest unit within the corpus.
A token has different attributes which are:
- Word : represents the token, the word as it appears written in the letters of the corpus.
- Lemma : represents the lemma attached to the token.
- PoS (Part of Speech) : represents the grammatical nature of the token in the letter.
In the Word and Lemma search fields, you can either enter the attribute values or upload your list of searched values.
In the Part of Speech search fields, you can select the searched value.
Then press Enter or click the Search button to execute the search and display the results.
Please note that there is an important difference between the Word and Lemma search fields.
Example: typing the word "aimer" in Word will only give you occurrences of that exact string.
When you enter "aimer" in the Lemma search field, you will get - in addition to the lemma "aimer" - all word forms related to that lemma, i.e. its forms in all tenses and moods ("j'aimerai", "nous aimions", etc.) as well as spelling variations, forms incorrectly written by authors (e.g. "j ème", "émé", etc.).
In the Extended search, in order to allow the search of specific and complex word forms, the use of wildcards is always highlighted in the search with the Word and Lemma fields.
As a reminder, a wildcard is a symbol used to replace or represent one or more characters.
As for the simple search, the wildcards that can be used here are:
- * : The asterisk that matches any character zero or more times.
-
? : The question mark matches an unknown character.
- | : The vertical bar offers an alternative
For the Word and Lemma search fields, it is also possible to search for a sequence, a series of tokens by entering several values, including wildcards, separated by a space.
Example: in Word, typing 'je n* * pas' means that we are looking for a first token 'je' followed by a second starting with 'n-', a third random token and a last token 'pas'.


On the right side of the Word and Lemma search fields, there is an option to upload a list of values to search for;
these values must all be separated by a white space. Note that this function only works for .txt files.
(If you are using a text editor like Word, you must first save your file in .txt format.)
Each word in the uploaded file will be added to the list of values to search for.
You can start a new search by pressing the Reset button.
Doing so will clear the search query and the results found.
Your search history will remain unchanged, however.
Advanced Search (Advanced)
Advanced Search allows you to create complex queries without needing to master the CQL (Corpus Query Language) query language.
The basic element of Advanced Search and its query builder is the token box. A box represents a
token. By clicking on the blue '+' icon, you can add an unlimited number of token boxes, the set thus forming a sequence.

A token box has two tabs: search and options.
The search
tab
The search tab of the token box allows you to define all the attributes or values that the token must or can have.
Token attributes
Specifying token attributes allows you to better focus and specify your search.
You can select a token attribute (Word, Lemma, POS) and enter the value it must or must not have.
A token box can combine several attributes.

The AND and OR options in the token boxes
By clicking on the white '+' button on the right in the token box,
you can add new attributes to your token with the AND (sets mandatory values) and OR (sets alternative values) options.

The AND option creates, in a clause, a new condition, a new attribute essential to your token.
 The object searched is all the words 'iron' which are verbs. Here we find 9 occurrences.
The object searched is all the words 'iron' which are verbs. Here we find 9 occurrences.
The OR option adds a new alternative, a new clause, a value that the token attribute can potentially take.
 The object searched is all the words 'fer' or all the tokens that are verbs. Here we will find 9,658 occurrences.
The object searched is all the words 'fer' or all the tokens that are verbs. Here we will find 9,658 occurrences.
The difference between the white '+' icons in the token box
The difference between the '+' sign on the right of a token and the one at the bottom of the token box is that the '+' sign
on the right keeps the newly added attribute in a subclause while the one at the bottom creates a new clause.
Example:
Suppose we want to search for all the words 'we' or 'you' used as a 'possessive adjective'.
If we only use the '+' on the right, we cannot apply the exclusivity of the search box to possessive adjectives.
 Here, the query will search for all the words 'we' (regardless of their POS) and the words 'you' whose POS is a possessive adjective.
Here, the query will search for all the words 'we' (regardless of their POS) and the words 'you' whose POS is a possessive adjective.
If we add the attributes using the '+' sign at the bottom of the token box, we can create a clause.
 By clicking the '+' at the bottom of the token box, we have created a clause that the query searches for all words with the value 'we' or 'you', to which is added the argument that the tokens searched for must have 'possessive adjective' for POS.
By clicking the '+' at the bottom of the token box, we have created a clause that the query searches for all words with the value 'we' or 'you', to which is added the argument that the tokens searched for must have 'possessive adjective' for POS.
Expert Search(Expert)
Expert search mode allows you to edit queries using the BlackLab Corpus Query Language, a dialect of the Corpus Query Language (CQL).
This language is used to query corpus texts using queries. CQL queries are expressions
constructed using sequence operators and block brackets, within which one or more token attributes are specified.
In CQL, spaces only affect a search if they are enclosed in quotes.
Some examples of searching with the BCQL language:
- Search for a word or a lemma: [word="ai"];[lemma="avoir"]
- More precise search for a word (reminder: a frame between brackets = a token, i.e. a word and its attributes): 1. [word="a" & lemma="à" & pos="prép." ] 2. [word="a" & lemma="avoir" & pos="verbe"].
In case 1, the query searches for all tokens whose character is 'a', the lemma is 'à' and the pos is 'prép'.
In case 2, the query searches for all tokens whose word is 'a', the lemma is 'avoir' and the pos is 'verbe'.
- Search with wildcards: [word=".*ent"] [lemma=".*er"] These searches match all words ending in '-ent' followed by a token whose lemma ends in '-er'.
NB: conversely in Simple Search, here remember to add a dot '.' in front of the asterisk '*' otherwise you will not get any results.
- Search according to POS (part of speech): [pos="adj."] This query searches for all adjectives in the corpus;
- Exclude a word, lemma or pos from the search: [word="tout" pos!="adv."] The '!=' element means 'not equal'. Here, the query searches for tokens whose word
is 'tout' but whose pos is different from 'adv.' (adverb).
- Search by combination of attributes:It is possible to use various operators to write complex queries:
- Right bar '|' for 'or' (ex:[word="ma"|"mon"] Here we search for the word "ma" or the word "mon"
- The ampersand '&' to indicate an addition of attributes: [word="a" & pos="prép."] Here the query searches for tokens with the word 'a' and whose part of speech is 'préposition'
- The repetition operators:We use the braces '{}' to define a sequence.
Example:
[pos="adj."]{2} matches a sequence of 2 adjectives;
[pos="adj."]{2,4}, we are looking for a sequence of 2 to 4 adjectives in a row.
[pos="adj."]{2,} this query matches the search for a sequence of 3 or more adjectives in a row.
- The empty brackets '[]' match any token: for example, [word="ma"][]{1,3}[word="mere"], this query returns all sequences where the words "ma" and "mere" are separated by 1 to 3 tokens.
For more information on CQL, click here.
The Macintosh corpus has been enriched with a set of metadata providing information on the letters (place of writing, author, year, place of arrival, etc.).
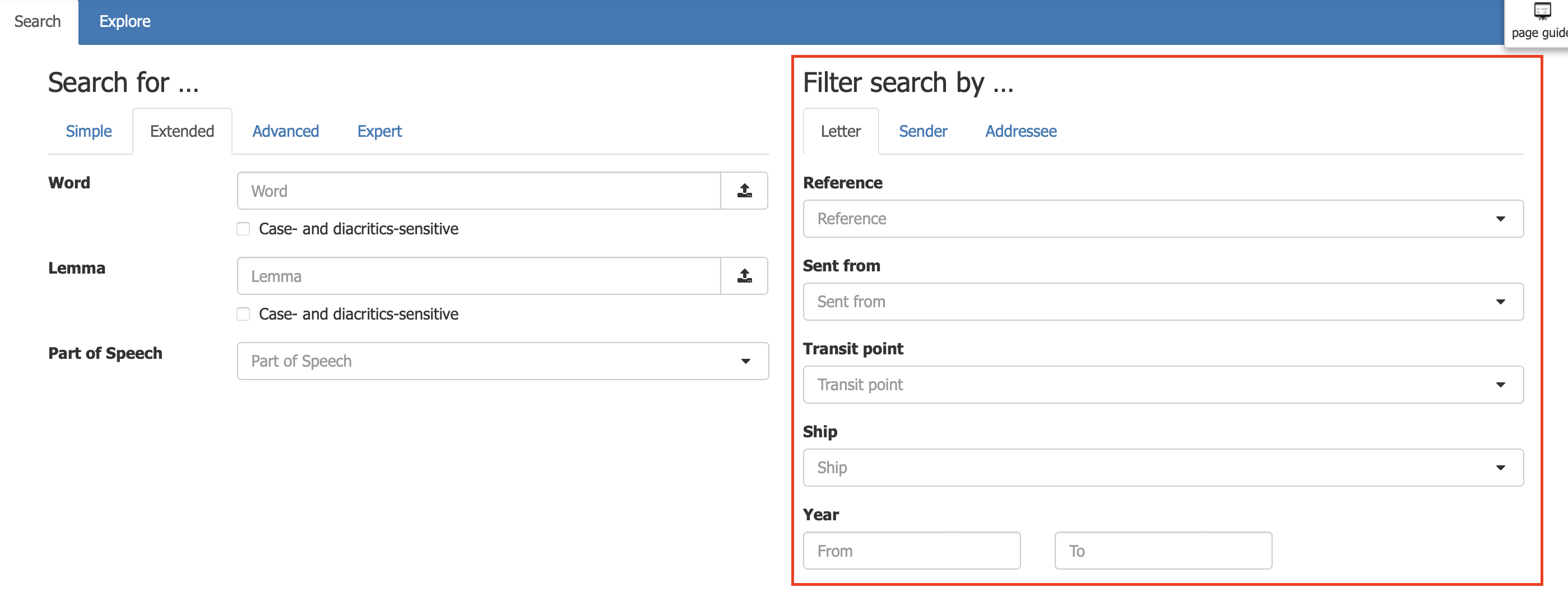
This metadata therefore allows you to filter and refine your search (in Extended, Advanced and Expert modes) with temporal, geographical and nominative requirements.
Below is a description of the metadata present on the search tool:
Letters
- Reference: this field allows you to enter the ratings of the letters you are looking for.
- Sent from: indicates the place from which the letter is sent.
- Transit point: indicates the transit point of the letter.
- Ship: this field allows you to find letters that mention a particular ship.
- Year: this field allows you to define a period for writing letters.
Sender
- Sender: indicates the name of the author of the letter.
- Sender's address: provides information on the address of the author.
Addressee
- Recipient: indicates the name of the recipient of the letter.
- Recipient's address: provides the address of the recipient.
Displaying results
The results can be viewed in two ways:
- Either by hit: the hit is defined as the token that corresponds to the result of the query.
- Or by document: displays the list of documents where the tokens searched for are present and indicates the number of tokens found per document.
Results by hit
If you click on one of the results of your search, you can display the properties and values of the token found as well as a text extract from which the token comes.
The result lines are always preceded by a line containing the name of the letter in which the token(s) were detected.
If you want, you can always hide the title of the documents by clicking on 'Hide Titles' at the bottom right of your screen at the bottom of your web page.
Show content and metadata of the letter
By clicking on the name of the letter or on the hyperlink above the token in the text extract, you will open a new tab showing you the content of the letter as well as the metadata relating to it.
Sort the results
You can click on the column headers to sort the results according to the values of this column, i.e. the attributes word, lemma or pos :
The headers in question:
- Before hit : Sorts the results by the term before the hit based on either its word, lemma or pos value.
- Hit : Sorts the found tokens based on their word, lemma or pos.
- After Hit: Sorts the results according to the term following the hit based on its word, lemma or pos.
- Lemma: Sorts the tokens based on the value of their lemma attribute.
- POS: Sorts the tokens based on the value of their part of speech.
You can also sort your results using the 'Sort by ... ' tab at the bottom right of the results table. Clicking on it will open a drop-down menu and allow you to sort the results based on the attributes of Hit, Before hit, After hit, as well as the letters' metadata.

Group results
It is also possible to group your hits. Once your search is done, at the top left of the results table, you can click on 'Group hits by ...'.

Next, you can select a grouping type.
The grouping criteria are the same as the sorting criteria. Once you have determined your grouping criteria,
the tool will show you groups of results.
 Here we have chosen to group the results by lemma.
Here we have chosen to group the results by lemma.
By clicking on one of the groups obtained, you will be able to access the search tool again with only the letters of the chosen group by clicking on 'View detailed concordances'

 By clicking on 'View detailed concordances' we have grouped here the results having 'vous' as lemma.
By clicking on 'View detailed concordances' we have grouped here the results having 'vous' as lemma.
Among the grouping criteria, you will however notice that there is a new one, Context (advanced). This option allows you to group the results by delimiting a context. You can thus choose the nature of the hits (word, lemma, pos) and especially delimit (from 1 to 5 tokens) the number of hit, before hit and after hit to display.
Export results
Search results can be exported by clicking on the 'Export' or 'Export for Excel' buttons at the bottom right of the results table. The first button exports the results to a .csv file while the second exports them to a .csv file more suitable for Excel software.
Once a search is done, you can click on the title of a document or the hyperlink of a token to open a new tab, the Content tab which contains the transcription of the letter.

Content
The results of the current query will be highlighted in underline, bold and red in the document transcript.
In case of multiple results, only the current result will also appear grayed out. You can navigate from one result to another by using
the arrows of the Hits button.

If you hover your cursor over a specific word in the document a
pop-up window will appear with the word's lemma and the Show details option. By clicking Show details , you
will see additional information at the word level such as its POS and explanations of its transcription and meaning.
Metadata
In this tab, all the metadata properties of the letter are displayed and provide information.
Statistics
The Statistics tab displays several statistics of the document: the number of tokens, the number of unique word forms, the number of lemmas and the unique word/token ratio.
It is possible to print or download these statistics via the drop-down menu to the right of the Distribution of parts of speech in the letter title.
Images
In this tab, you will find images of the transcribed letters with tools to zoom or orient the images.
The Explore
interface
The Explore
tab
This tab has three subdivisions:
- Documents
- N-grams
- Statistics
Documents
'Documents' allows you to group letters according to their metadata (recipient, sending location, etc.).
This tab allows you to group letters from the corpus according to metadata (geographic location, dates, etc.).
N-grams
N-grams allows you to list the frequency of N-elements (word, lemma, pos) in the corpus. In a way, it is a simplified version for searching and grouping sequences.
To do this, you have different options:
- N-gram size: the length of the sequence (a number from 1 to 5; the default setting is 5)
- N-gram type: choose for sequences of word (i.e. the form of the word), lemma or part of speech. If you
do not specify the search term further, a series of five consecutive words, lemmas or parts of speech
will be searched.
You can still filter your results using metadata.
Statistics
With Statistics you can create comprehensive frequency lists of all words, lemmas or Part of Speech in the corpus.
Options for creating lists:
- Frequency list type: Choose the word lists (i.e. word form), lemma, part of speech and part of speech + features
- Filter search by ...: As usual, you can filter the results based on metadata, sort them and group them.
Example: It is possible to determine the use of the ten most frequent words by women by searching for the frequency list type 'Word' and filtering the search by 'sex'.