La recherche Simple permet d'effectuer une recherche rapide par mots ou par lemme.
Pour effectuer une recherche, il suffit simplement d'entrer le mot recherché dans la barre de recherche et d'appuyer sur Entrée ou de cliquer sur Search.
A noter: dans la recherche Simple, les recherches sont insensibles à la casse, c'est-à-dire que les accents ou majuscules et minuscules ne sont pas pris en compte: ainsi les recherches "mère", "mere, "Mère", "Mere" fourniront les mêmes résultats.
De plus, il est possible pour d'utiliser des caractères génériques afin d'affiner le niveau de la recherche:
* : L'astérisque représente n'importe quel caractère apparaissant zéro ou plusieurs fois.
Exemple: une recherche "me*" permet de relever tous les mots commençant par 'me-';
une recherche "*me" permet de relever tous les mots se terminant par '-me';
une recherche "m*e" permet de relever tous les mots commençant par 'm-' et se terminant par '-e';
une recherche "m*e*" permet de relever tous les mots commençant par 'm-' et comportant un 'e';
? : Le point d'interrogation représente un caractère inconnu.
Ainsi, entrer 'm?' permet de chercher tous les mots dans les lettres commençant par un 'm-' suivi d'un seul caractère;
une recherche 'm??' permet de chercher tous les mots commençant par un 'm-' suivi de deux caractères;
une recherche '????m' permet de chercher tous les mots se terminant par un '-m' précédé par quatre caractères;
| : La barre verticale symbolise 'ou' et propose une alternative.
Si vous entrez une recherche comme 'm*|n*', vous exprimez que vous recherchez toutes les chaînes de caractères commençant par 'm' ou toutes les chaînes de caractères commençant par 'n'.
Recherche Etendue (Extended)
La recherche Etendue est un prolongement de la recherche Simple et vous permet de retrouver toutes les occurrences d'un token avec ses attributs spécifiques.
Un token représente généralement un seul mot et est la plus petite unité au sein du corpus.
Un token possède différents attributs qui sont :
Word : représente le token, le mot tel qu'il apparaît écrit dans les lettres du corpus.
Lemma : représente le lemme rattaché au token.
PoS (Part of Speech) : représente la nature grammaticale du token dans la lettre.
Dans les champs de recherche Word et Lemma, vous pouvez soit rentrer la valeur des attributs, soit télécharger votre liste des valeurs recherchées.
Dans les champs de recherche Part of Speech vous pouvez sélectionner la valeur recherchée.
Appuyez ensuite sur Entrée ou cliquez sur le bouton Rechercher pour exécuter la recherche et afficher les résultats.
Veuillez noter qu'il existe une différence importante entre les champs de recherche Word et Lemma.
Exemple : saisir la mot "aimer" dans Word ne vous fournira que les occurrences de cette chaîne exacte
de caractères. Lorsque vous entrez "aimer" dans le champ de recherche Lemma, vous obtiendrez - en plus du lemme "aimer" - toutes les formes de mots liées à ce lemme, comme c'est-à-dire ses formes à tous les temps et tous les modes ("j'aimerai", "nous aimions", etc.) ainsi que des variantes orthographiques, des formes incorrectement écrites par les auteurs (ex:"j ème", "émé", etc.).
Dans la recherche Etendue, afin de permettre la recherche de formes de mots spécifiques et complexes, l'utilisation de caractères génériques est toujours mise en avant dans le cadre de la recherche avec les champs Word et Lemma .
Pour rappel, un caractère générique est un symbole utilisé pour remplacer ou représenter un ou plusieurs caractères.
Comme pour la recherche simple, les caractères génériques utilisables ici sont :
* : L'astérisque qui correspond à n'importe quel caractère zéro ou plusieurs fois.
? : Le point d'interrogation correspond à un caractère inconnu.
| : La barre verticiale propose une alternative
Pour le champ de recherche Word et Lemma, il est également possible de rechercher une séquence, une série de jetons en saisissant plusieurs valeurs, y compris avec des caractères génériques, séparés par un espace.
Exemple: dans Word, taper 'je n* * pas' signifie que l'on cherche un premier token 'je' suivi d'un second commençant par 'n-', d'un troisième quelconque et un dernier token 'pas'.
À droite sur les champs de recherche Word et Lemma, il y a une option pour télécharger une liste de valeurs à rechercher ;
ces valeurs doivent toutes être séparées par un espace blanc. Notez que cette fonction ne fonctionne que pour les fichiers .txt.
(Si vous utilisez un éditeur de texte comme Word, vous devez d'abord enregistrer votre fichier au format .txt.)
Chaque mot du fichier téléchargé sera ajouté à la liste des valeurs à rechercher.
Vous pouvez lancer une nouvelle recherche en appuyant sur le bouton Réinitialiser.
Ce faisant, la requête de recherche et les résultats trouvés disparaîtront.
Votre historique de recherche restera cependant inchangé.
Recherche Avancée (Advanced)
La recherche Avancée permet de créer des requêtes complexes sans besoin de maîtriser le langage de requêtes CQL (Corpus Query Language).
L'élément de base de la recherche Avancée et de son générateur de requêtes est la boîte à token. Une boîte représente un
token. En cliquant sur l'icône bleu '+', vous pouvez rajouter un nombre illimité de boîte à token, l'ensemble formant ainsi une séquence.
Une boîte à token comporte deux onglets : search et options.
L'onglet search
L'onglet search de la boîte à token permet de définir l'ensemble des attributs ou valeurs que le token doit ou peut posséder.
Les attributs du token
La spécification des attributs de token permet de mieux centrer et spécifier sa recherche.
Vous pouvez sélectionner un attribut du token (Word, Lemma, POS) et saisir la valeur qu'il doit avoir ou non.
Une boîte à token peut combiner plusieurs attributs.
Les options AND et OR dans les boîtes à token
En cliquant sur le bouton blanc '+' à droite dans la boîte à token,
vous pouvez ajouter de nouveaux attributs à votre token avec les options AND (définit des valeurs obligatoires) et OR (définit des valeurs alternatives).
L'option AND crée, dans une clause, une nouvelle condition, un nouvel attribut indispensable à votre token.
L'objet recherché est tous les mots 'fer' qui sont des verbes. On trouve ici 9 occurences.
L'option OR ajoute une nouvelle alternative, une nouvelle clause, une valeur que l'attribut du token peut potentiellement prendre.
L'objet recherché est tous les mots 'fer' ou tous les tokens qui sont des verbes. On trouvera ici 9 658 occurences.
La différence entre les îcones '+' blancs de la boîte à token
La différence entre le signe '+' à droite d'un token et celui situé dans le bas de la boîte à toke est que le signe '+'
à droite conserve l'attribut nouvellement ajouté dans une sous-clause tandis que celui du bas crée une nouvelle clause.
Exemple :
Supposons que nous voulions rechercher tous les mots 'nous' ou 'vous' utilisés comme 'adjectif possessif'.
Si nous n'utilions que le '+' à droite, nous pouvons pas appliquer l'exclusivité du champ de recherche aux adjectifs possessifs.
Ici, la requête va rechercher tous les mots 'nous' (qu'importe leur POS) et les mots 'vous' dont le POS est adjectif possessif.
Si nous ajoutons les attributs en utilisant le signe '+' en bas du de la boîte à token, nous pouvons créer une clause.
En cliquant sur le '+' en bas de la boîte à token, nous avons créé une clause selon laquelle la requête cherche les tous mots ayant pour valeur 'nous' ou 'vous', clause à laquelle vient se rajouter l'argument que les tokens recherchés doivent avoir 'adjectif possessif' pour POS.
Recherche Expert (Expert)
Le mode de recherche Expert permet d'éditer des requêtes par le biais du langage BlackLab Corpus Query Language, un dialecte du Corpus Query Language (CQL).
Ce langage est utilisé pour interroger les textes des corpus par le biais de requêtes. Les requêtes CQL sont des expressions
construites à l'aide d'opérateurs de séquence et de crochets de blocs, à l'intérieur desquels un ou plusieurs attributs de token sont spécifiés.
En CQL, les espaces n'affectent une recherche que s'ils sont inclus entre guillemets.
Quelques exemples de recherche avec le langage BCQL:
Rechercher un mot ou un lemme : [word="ai"];[lemma="avoir"]
Recherche plus précise d'un mot (rappel: un encadrement entre crochets = un token, c'est-à-dire un mot et ses attributs) : 1. [word="a" & lemma="à" & pos="prép." ] 2. [word="a" & lemma="avoir" & pos="verbe"]. Dans le cas 1, la requête cherche tous les tokens dont le caractère est 'a', le lemme est 'à' et le pos est 'prép'. Dans le cas 2, la requête recherche tous les tokens dont le mot est 'a', le lemme est 'avoir' et le pos 'verbe'.
Rechercher avec des caractères génériques : [word=".*ent"] [lemma=".*er"] Ces recherches correspondent à tous les mots se terminant par '-ent' suivi d'un token dont le lemme se terminant par '-er'. NB : à l'inverse dans la Recherche Simple, ici pensez à rajouter un point '.' devant l'astérisque '*' sinon vous n'obtiendrez aucun résultat.
Rechercher en fonction du POS (part of speech): [pos="adj."] Cette requête recherche tous les adjectifs du corpus;
Exclure un mot, un lemme ou pos de la recherche : [word="tout" pos!="adv."] L'élément '!=' signifie 'pas égale'. Ici donc, la requête cherche les tokens dont le mot
est 'tout' mais dont le pos est différent de 'adv.' (adverbe).
Recherche par combinaison d'attributs : Il est possible d'utiliser divers opérateurs pour écrire des requêtes complexes:
Barre droite '|' pour 'ou' (ex:[word="ma"|"mon"] Ici on recherche le mot "ma" ou le mot "mon"
L'esperluette '&' pour indiquer une addition d'attributs: [word="a" & pos="prép."] Ici la requête recherche les tokens avec le mot 'a' et dont le part of speech est 'préposition'
Les opérateurs de répétitions: On utilise les accolades '{}'pour définir une séquence.
Exemple:
[pos="adj."]{2} correspond à une séquence de 2 adjectifs;
[pos="adj."]{2,4}, on recherche une séquence de 2 à 4 adjectifs à la suite.
[pos="adj."]{2,} cette requête correspond à la recherche d'une séquence de 3 ou plus d'adjectifs à la suite.
Les crochets vides '[]' correspondent à n'importe quel token : par exemple, [word="ma"][]{1,3}[word="mere"], cette requête ressort toutes les séquences où les mots "ma" et "mere" sont séparés par 1 à 3 tokens.
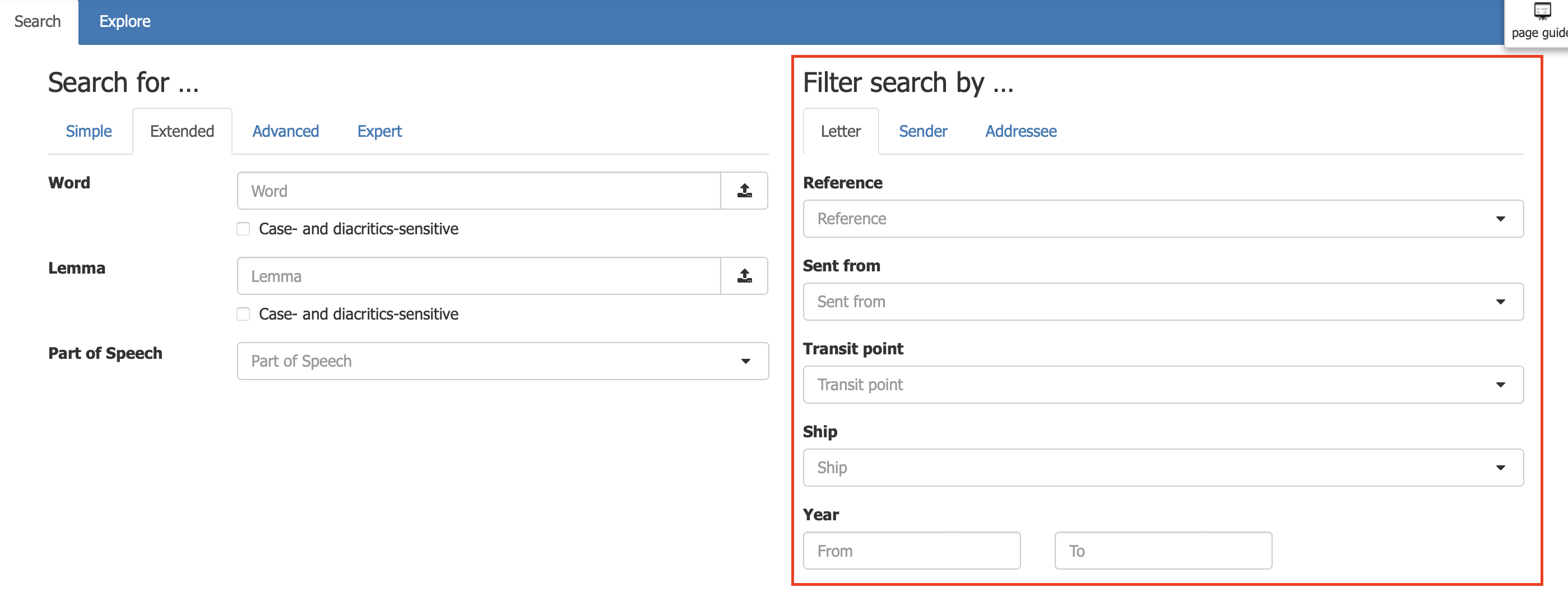
Le corpus Macintosh a été enrichi d'un ensemble de métadonnées fournissant des informations sur les lettres (lieu d'écriture, auteur, année, lieu d'arrivée, etc.).
Ces métadonnées permettent donc de filtrer et d'affiner la recherche (en mode Extended, Advanced et Expert) avec des exigences temporelles, géographiques et nominatives.
Ci-dessous se trouve une description des métadonnées présentes sur l'outil de recherche:
Letters
Reference : ce champ permet de renseigner les cotes des lettres recherchées.
Sent from : indique le lieu d'où la lettre est envoyée.
Transit point : indique le point de transit de la lettre.
Ship : ce champ permet de retrouver des lettres faisant mention de navire en particulier.
Year : ce champ permet de définir une période de rédaction des lettres.
Sender
Sender : indique le nom de l'auteur de la lettre.
Sender's address : renseigne sur l'adresse de l'auteur.
Addressee
Recipient : indique le nom du destinataire de la lettre.
Recipient's address : renseigne l'adresse du destinataire.
Affichage des résultats
Les résultats peuvent être visualisés de deux façons:
Soit par hit : le hit est défini comme le token qui correspond au résultat de la requête.
Soit par document: affiche la liste des documents où sont présents les tokens recherchés et indique le nombre de token trouvé par document.
Les résultats par hit
Si vous cliquez sur une des résultats de votre recherche, vous pourrez afficher les propriétés et les valeurs du token trouvé ainsi qu'un extrait de texte dont le token est issue.
Les lignes des résultats sont toujours précédées d'une ligne contenant le nom de la lettre dans laquelle le ou les tokens ont été détectés.
Si vous voulez, vous pouvez toujours masquer le titre des documents en cliquant en bas à droite de votre écran sur 'Hide Titles' tout en bas de votre page web.
Affiche du contenu et des métadonnées de la lettre
En cliquant sur le nom de la lettre ou sur l'hyperlien au-dessus du token dans l'extrait du texte, vous ouvrirez un nouvel onglet vous présentant le contenu de la lettre ainsi que les métadonnées relatives à cette dernière.
Trier les résultats
Vous pouvez cliquer sur les en-têtes des colonnes afin de trier les résultats selon les valeurs de cette colonne, c'est-à-dire les attributs word,lemma ou pos :
Les en-têtes en question :
Before hit : Fait le tri des résultats selon le terme précédant le hit en fonction soit de sa valeur word, lemma ou pos.
Hit : Fait le tri tokens trouvés en fonction de leur word, lemma ou pos.
After Hit : Fait le tri des résultats selon le terme suivant le hit en fonction de son word, lemma ou pos.
Lemma : Fait le tri des tokens en fonction de la valeur de leur attribut lemma.
POS : Fait le tri des tokens en fonction de la valeur de leur part of speech.
Vous pouvez aussi trier vos résultats grâce à l'onglet 'Sort by ... ' en bas en droite du tableau de résultat. En cliquant dessus, vous ouvrirez un menu déroulant et pourrez trier les résultats en fonction des attributs de Hit, Before hit, After hit, ainsi qu'en fonction des métadonnées des lettres.
Regrouper les résultats
Il est possible aussi de regrouper vos hits. Une fois votre recherche effectuée, en haut à gauche du tableau des résultats, vous pouvez cliquez sur 'Group hits by ...'.
Ensuite, vous pouvez sélectionner un type de regroupement.
Les critères de regroupement sont les mêmes que les critères de tri. Une fois votre critère de regroupement déterminé,
l'outil vous affichera des groupes de résultats.
Ici nous avons choisi de regrouper les résultats par lemme.
En cliquant sur l'un des groupes obtenus, vous pourrez accéder de nouveau à l'outil de recherche uniquement avec les lettres du groupe choisi en cliquant sur 'View detailled concordances'.
En cliquant sur sur 'View detailled concordances' nous avons regroupé ici les résultats ayant 'vous' pour lemme.
Parmi les critères de regroupement, vous pourrez toutefois remarquer qu'il s'en trouve un nouveau, Context (advanced). Cette option vous permet de regrouper les résultats en délimitant un contexte. Vous pouvez ainsi choisir le nature des hits(word, lemma, pos) et surtout délimiter (de 1 à 5 tokens) le nombre de hit, before hit et after hit à afficher.
Exporter les résultats
Les résultats de recherche peuvent être exportés en cliquant en bas à droite du tableau de résultats sur les boutons 'Export' ou 'Export for Excel'. Le premier bouton exporte les résultats dans un fichier .csv tandis que le second les exporte dans un fichier .csv plus adapté pour le logiciel Excel.
Les informations et la visualisation d'une lettre
Une fois une recherche effectuée, vous pouvez cliquer sur le titre d'un document ou l'hyperlien d'un token afin d'ouvrir un nouvel onglet, l'onglet Content qui contient la transcription de la lettre.
Content
Les résultats de la requête actuelle seront mis en évidence en souligné, gras et rouge dans la transcription du document.
Dans le cas de plusieurs résultats, seul le résultat actuel apparaîtra également en grisé. Vous pouvez naviguer d'un résultat à l'autre en utilisant
les flèches du bouton Hits.
Si vous passez votre curseur sur un mot spécifique dans le document une
fenêtre contextuelle apparaitra avec le lemme du mot et l'option Show details. En cliquant sur Show details , vous
verrez des informations supplémentaires au niveau du mot comme son POS et des explications sur sa transcription et sa signification.
Lecture des lettres
Metadata
Dans cet onglet, toutes les propriétés des métadonnées de la lettre sont affichées et fournissent des informations.
Statistics
L'onglet Statistics affiche plusieurs statistiques du document : le nombre de tokens, le nombre de formes uniques de mots, le nombre de lemmes et le ratio mot unique/token.
Il est possible d'imprimer ou de télécharger ces statistiques via le menu déroulant à droite du titre Distribution of parts of speech in the letter.
Images
Dans cet onglet, vous trouverez les images des lettres transcrites avec des outils afin de zoomer ou orienter les images.
L'interface Explore
L'onglet Explore
L'onglet Explore permet d'explorer et de regrouper les lettres du corpus.
Cet onglet comporte trois subdivisions:
Documents
N-grams
Statistics
Il comporte aussi un champ 'Filter search by...' qui permet de filtrer les résultats des 3 modes d'exploration en remplissant les champs des métadonnées.
Documents
'Documents' permet de faire un regroupement des lettres selon différents critères de sélections.
Il est composé de deux champs avec des listes déroulantes:
Grouped documents by metadata: champ qui permet de spécifier selon quel critère de metadonnées (destinateur, destinateur, lieu de transit, etc.) les lettres doivent être regroupées.
Show group as: permet de sélectionner sous quelle forme l'on souhaute afficher les résultats:
docs : regroupe les résultats et indique pour chaque résultats le nombre de lettres contenues.
Affichage sous la forme 'docs' des groupes de lettres trouvées en les regroupant par auteur. On remarque que pour chaque groupe est indiqué le nombre de lettres contenues.
tokens : regroupe les résultats et indique pour chaque résultats le nombre de tokens contenus.
Affichage sous la forme 'tokens' des groupes de lettres trouvées en les regroupant par auteur et indiquant pour chaque groupe le nombre de tokens contenus.
table : affiche les résultats sous la forme d'un tableau avec des colonnes conjuguant les données transmises aux formats 'tokens' et 'docs'.
Affichage sous la forme 'table' des groupes de lettres trouvées en les regroupant par auteur.
Dans les visions de résultats 'docs' et 'tokens', une fois les résultats affichés, vous pouvez cliquer sur l'un d'entre eux afin d'afficher et étudier les lettres du sous-corpus en cliquant sur l'icône 'View detailled concordances'.
N-grams
N-grams permet de répertorier des séquences de N-éléments (word, lemma, pos) dans le corpus.
Vous pouvez écrire des séquences allant de 1 à 5 éléments.
Pour se faire, vous disposez de différentes options:
N-gram size : définissez le nombre d'éléments que la séquence doit contenir, un nombre de 1 à 5 ; par défaut vous recherchez des séquences composées de 5 éléments
N-gram type : définissez sous quelle forme les séquences et résultats doivent être affichés (sous la forme de mot, de lemme ou de PoS)
Une fois ces paramètres définis, vous pouvez compléter votre recherche et exploration en précisant pour chaque élément de votre séquence la forme (word, lemma, PoS) et la valeur du token recherché.
Ici, nous avons défini notre exploration en sélectionnant une séquence composée de 3 éléments et souhaitez afficher les résultats sous la forme de mots ('Word'). Notre recherche a ensuite été affinie en précisant que dans nos séquences, le premier élément devait être un token ayant 'je' comme valeur de 'Word', le second élément doit avoir pour 'ne' pour lemme et enfin un troisième élément dont la nature grammaticale doit être un 'verbe'.
Voici les résultats que l'on obtiendra :
Statistics
Avec Statistics
vous pouvez dresser des listes exhaustives de fréquences de l'ensemble des mots, lemmes ou Part of Speech du corpus.
Options pour dresser des listes:
Frequency list type : Choisissez les listes de mots (c'est-à-dire forme de mot), lemme, partie du discours et partie du discours + caractéristiques
Filter search by ... : Comme d'habitude, vous pouvez filtrer les résultats en fonction des métadonnées, les trier et les regrouper.
Exemple : Il est possible de déterminer l'utilisation des dix mots les plus fréquents par les femmes en recherchant le type de liste de fréquences 'Word' et en filtrant la recherche par 'sex'.